

Why am I sharing this, and why might another rider want to read this?
I'm a (modestly) credentialed, (modestly) working scientist with no present affiliation to the any part of the bike industry. Teaching quantitative reasoning and technical communication skills is the lion's share of what I do for work. I'm not a 'sci-comm' professional trying to drive attention toward a podcast about bikes or a bike youtuber trying to grab attention by deploying keywords like data or science. I don't have a vested interest in either bike setup being faster than the other. So let this be my attempt at a guide by example to reading bike science better or making bike science better. Here is a data set which I measured myself. This means I can share the methodology behind the data and help to assess the strength of any inferences or insights we may make from the data.
I'm not going to reveal at the end that Setup A and Setup B are the first and second most expensive forks on the market. It's not a review. I ride two bikes and neither has that stuff. They are different. But how different? How do we talk in a way that is not bogus or hyperbolic about differences? Read on!
How were these data collected?
Chip timers were attached to the fork of each bike A and B for the duration of the test. This timing system works on a predetermined track segment and measured elapsed time between a static start and the bike passing by the ending sensor, similar a chip-timed DH race run between the start gate and the first split. The static start eliminated needing to standardize the entry speed to the segment. Lap times for the segment were collected across numerous days in 2024, with a session of data collection following the schedule ABABAB for six total laps timed per day of riding. The complete schedule of six laps wasn't possible to record some test days, and these days were noted for possible exclusion from the analysis. Laps that failed for any reason to be a full effort start-to-finish by the test rider were noted for possible exclusion from the analysis. Further details of data cleaning will be discussed later.
What questions have been asked of the data so far?
To what extent are Bike Setup A and Bike Setup B different as measured by lap times?
To what extent does lap order within a session matter as measured by lap times?
How much of the difference in lap times can be attributed to the difference in bike setup A or B, versus other non-equipment factors not controlled in the experiment?
Let's take a first look at the data. This is a graph specifically formatted for readability of the raw data. They are spread out in space in a way that makes each point visible but distorts one axis. A lot of caution should be taken making inferences for reasons I'll try to cover, but this format is better in many ways than showing a large table to provide a look at the entire, raw, set of data.
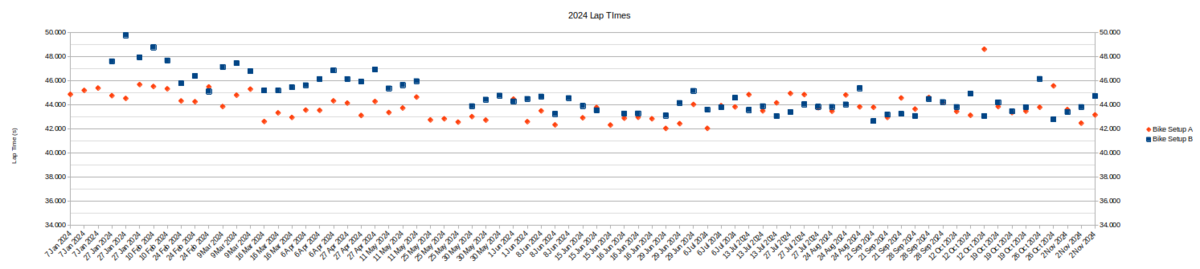
Looking down at the unedited big picture, let's see what we can see.
This is wild! That's a lot of practice on the same trail. Betting you have every rock, bump, and line burned in your memory now.
If I'm eyeballing lines of best fit for A and B for the graph you shared, it seems like A starts out slower than B, then they converge to be equivalent by the end of June through the end of the test in November. At the widest point of variance between A and B, it's about 3 seconds (46-ish seconds per lap for A vs. 49 seconds for B, eyeballing lines of best fit). Which is not nothing, that's a 6+% difference. And n=70 for each set is pretty decent!
Now tell me why I'm wrong and all my assumptions are stupid.
[Edit: B is slower than A in the graph, duh, my bad]
this is awesome!
You were consistently slower on B through May and had a wider variation of times compared to setup A. In June, the times started looking much similar. Setup A remained consistent with less variation throughout the whole period. It points that setup B was likely newer and less familiar as it got better, while A remained about the same pointing to a setup you were previously familiar with. Setup B you got about 10% faster with throughout the year, while A looks to remain flat and both look about the same time by end of year.
With the raw data I would break it down by Min, Max, Median, Average by month. My assumption is that your variance from Min to max decreased more on setup B from May to October. I'd be curious to know what one was better in October by those aggregations as they look about the same visually and its hard to differentiate.
It has been a while since I did much statistics and I never fancied it much, but if you do a z-test what do you get?
Oh man! This initially seems perfect for a paired t-test as your methods are going to allow you to control for changing conditions across days! However, the trend toward convergence across time does make me question the assumption of a “random sample of days.”
Specifically, I am curious if bike setup A was your standard setup going into the test (or closer to it), and if we are seeing how long it takes for you to reach your peak pace on a new bike. Alternatively, are we seeing the gap close because the transition into summer and fall reduces some sort of trail conditions-related benefit present in the winter and spring (seasonality)?
Looking forward to following this thread! I love when I get to combine stats and mtb!
Two-Way ANOVA (predict lap times according to factors of bike and date) and include an interaction effect. Then if present you can test the slope of the regression lines to determine the rate of change in lap times differs between bikes (Team Robots) notes above!
What was the difference between bike A and B? At the end of May/start of June you found something with bike set B. But, interestingly, on an average day you rode better on bike setup A. it would be interesting to hear what you were testing or trying?
Based on the fact that the only portion of the data that could maybe be considered significantly different is winter through early spring, it would actually be interesting to look at how conditions may factor in. I could see there being a chance that setup A is only faster in wet cold months and otherwise essentially the same.
MaxxTerra on Bike B, MaxxGrip on Bike A. Rider got faster with practice and Bike A tyres wore out.
Would you be willing to send a file with the raw data? I am an Engineer in the industry and would like a stab at doing some analysis on that to maybe answer some questions and pull-out contributing factors.
Nice to see the nerds are out in force. Fun topic and data set to discuss, so thanks for that.
I deal with these sorts of "basic" data sets and the questions that come with them regularly at the World Cups as that is a big part of my role as coach at the races. The general lack of rigour and understanding of causality, causation, error, trial-to-trial variability etc.. at the races and generally in the bike industry is pretty surprising. But sadly, strict materialist/reductionist/mechanistic philosophies dominate without any awareness of that domination for a lot of people
I won't comment much on applying classical statistical analysis to the data set provided, as others have done a great job already unpacking potential ways to investigate and infer from the data set. Of note though is the seeming lack of an initial commitment to either inductive, deductive or even abductive reasoning? I think this is key to lay out first, as otherwise some HARKing may happen (as it almost always does at the races and in the bike industry).
As we are already assuming this is Northern hemisphere data and as such the weather/seasons are playing a big role in the "learning effect" on display in both set-ups, a further "descriptive conversion" of the data would be really helpful. For example, knowing certain track characteristics and how they might interact with the set-ups and weather/seasonal changes would be highly valuable. The positivistic tradition of the "data will know best" regardless of context is seldom tenable in the non-linear interactions of complex systems.
Your question around trial order is really interesting though, honestly impressive you stuck to the ABAB order. The motor learning and control research is pretty dense with investigations into the impact of random, blocked, mixed practice orders etc... and again the bike industry in general is not aware of the centuries old research in this area. Sadly most of the research is around key pressing exercises in labs, or if it is sport related then it's often targeting/aiming or ballistic tasks like volleyball shots. So hard to extrapolate to something as variable as MTB.
What is of note though, is that your ABAB order or an AABBAABB order is usually the most common when testing things (bikes/tyres/parts), this comes again with the assumption of linearity and mechanistic functioning of humans. So while the bike is a complicated system the human is not, the human is complex. And depending on what theories of motor learning you sign up too ( there are many) then the implications of trial order are quite interesting. If the human needs a certain amount of time to "calibrate" or attune to the changes in task, equipment or environment, then an ABAABBA order might be best, but again all these interactions are non-linear. So it's hard to make blanket recommendations, especially if we want to account for fatigue. The difficulty of the track and the magnitude of set-up change need to be known quantities(and maybe qualia), even if "blind" in some way to the participant. Likewise the ability of the rider is a key variable. As their "knowledge of" - so how good they can ride any terrain, interacts with their "knowledge about" abilities - so their ability to rapidly interpret what a set-up change may mean and how they could preemptively adjust their interaction with the track is highly individual dependant but a key performance variable in testing "set-ups".
Long story short, I'm really looking forward to more insight/data if it's coming, but I would remain skeptical that a clear inductive process of data-pattern-conclusion (even if the conclusion is probabilistic). It is a big commitment to make when the non-linearity of rider-bike-track interactions is not accounted for.
Early observations and new questions
With the benefit of the big picture and despite the funny business with the "time" axis having a misleading scale, y'all can just see that Bike Setup B approaches and maybe even ends up faster than Bike Setup A, eventually. I'll show how I did the statistical tests in the next post and ask if it seems convincing and how you might have done it differently. But I think some cool things happened in the early observations. Here's when the parts started appearing that I think might help others as they think about their testing, and I can give a little more of the story.
Just like people have said, the test rider comes out of the winter holidays and New Year having built up the new, untested bike, Setup B. Setup A has been around for long enough to be familiar. The first day isn't even a test day, just a chance to ride a few laps and see where things stand. I did a few laps on Setup B but hadn't gotten the second timing chip or the method or questions firmly in my mind yet. I just wanted to know if Bike Setup B was good! The next session marks the beginning of the sampling and it could have stopped right then
Setup B is not good!
I can imagine writing up a little bike review in February. Hey guys, I did an untimed session first week of January to shake down the new bike and see where my body was at after all the Christmas cookies. I did timed testing at the same track three weeks later with three runs each, ABABAB, and didn't have any crashes or big mistakes or other reasons to cast doubt on the times. The weather was great. Setup B is just plain slower. 3 seconds slower. 7% slower. I went in the wrong direction and so it's time to start thinking about Bike Setup C!
But questions can change in light of new observations. I wanted to know about the difference between the two bikes. I took some measurements. But there were hints already that I was getting information not just about the bikes.
Look at the difference in consistency between the first 6 runs of Setup A and the first 3 runs of Setup B. The spread in A is less than the spread in B, despite having more runs (6 vs 3) logged on more days (2 vs 1). What are the plausible equipment reasons for Setup B to perform inconsistently?
Tire pressures? Suspension or brake inconsistency? The answer was no, not that I could find. So if it can't be explained by equipment performing inconsistently from run to run, then it's gotta be a non-equipment reason. Something in the environment or the rider. So the test I designed doesn't just test bikes. Dang it.
Possible patterns, possible explanations
Now that the door has cracked open to us considering that the test is capturing information that isn't simply about the nature (how fast?) of Bike Setup A versus Bike Setup B, a few more patterns jumped out. Lines of best fit are hypotheses, at least that's how I think of them. They aren't really in the data, but are a way of saying graphically and with math, if we draw this line and presume that there truly is a pattern here, what would that mean? And what would it predict in a way that we could test the prediction and get some evidence that the pattern really was there in the first place.
Here we are in mid March, and it's beginning to look like my A/B bike test is really timing things like fatigue(?) (orange lines) or a sort of 'practice effect'(?) (blue line). It's become a rider test! And who knows what else? If these confounding factors are mixed into the data, how do I use the data to answer my original question about whether A or B is faster?
Intriguing. Keep the posts coming. I hate that MTB markets crap without data to prove the benefit.
As an aside I'm amazed that setup B is slow at the start. Let's say it's a new bike, I would be quicker for sure on my very first run than my old bike (I know because I've also done accurate timed testing), but I wait a while before I'm certain that a new bike will be noticeable.
Came to share a similar sentiment, but your comment is very kindly worded.
Sometimes, when we have a hammer, everything begins to look like a nail. For those interested, I would suggest perusing a text like ‘design and analysis of experiments’ by Montgomery or similiar text. The first chapter of Montgomery’s book further discusses some of the experimental concepts brought up by PointOne and may steer you to a more appropriate experimental design as well as deeper thought about measurement.
I think I get what you're saying and I hope you'll correct me if I'm wrong. And I think you see what I'm doing with this thread, but if that's that case then I don't know that I'm totally getting what (I mean why) you're saying it :D
This data set is a dog's breakfast. OMG 140 laps. It's going to be a slaughter in the data cleaning step when more than half of the observations get thrown out. 🤕 I've only shared a picture of the data with everyone, but once I get the .csv up nothing will be in the way of anyone from drawing the same conclusion. The analysis is limited by a number of important and interesting factors to do with how it was collected. Important not just in the constraints they put on drawing inferences from this set, but important because they are representative of choices/mistakes/oversights that others may make while working with bike data. Look at riders' comments about testing or data acquisition, and you see it is very commonly thought of as collect first, try to interpret second, which is where these problems crop up. My colleague in bikes, thank you for seeing that is a major point of the thread :D
The other point of the thread, as I see it, is that hypothesis testing is not the end-all-be-all unless you are in the rat race for grant money and publication, or working on something truly important like drug trials. The two bikes are super obviously different. Spending the 'money' on improved rigor there is money poorly spent. I want to show some non-trivial, positive results here that are not reject of accept H0. My major goal may differ from another's, but I'm trying to get to the idea of effect size for an audience that either isn't interested in stats or is focused on hypothesis testing because that's what gets taught in school.
I appreciate the comments!
Another book to add to my list. You've summed it up succinctly though, we can do many things in experimentaion, measurment and design. As long as we are aware of our assumptions and their implications. Philosophy of and for experiments, as well as design and interpretation! They all come with assumptions, grounded in philosophy, whether we know we have them or not.
I think we are definitely on the same page, or at least on different pages in the same book! Looking forward to more, as your comments around the cycle of Gather-Interpret-Conculsion that makes up most testing/data acq. cycles in MTB is really the crux of the whole thing. Trial order alone is a controllable variable that is seldom talked about.
Data (Comma Separated Values). Copy-paste into a text file and save as .csv. Open .csv in any spreadsheet or stats application. It may be that your preferred application will allow you to copy-paste directly and it may not.
@Con Rad-ish
Date,Order,Bike Setup A,A Flagged,Bike Setup B,B Flagged
7 Jan 2024,first,44.883,N,,
7 Jan 2024,second,45.213,N,,
7 Jan 2024,third,45.405,N,,
27 Jan 2024,first,44.774,N,47.631,N
27 Jan 2024,second,44.547,N,49.793,N
27 Jan 2024,third,45.698,N,47.961,N
10 Feb 2024,first,45.538,N,48.789,N
10 Feb 2024,second,45.345,N,47.698,N
24 Feb 2024,first,44.338,N,45.795,N
24 Feb 2024,second,44.275,N,46.411,N
24 Feb 2024,third,45.501,N,45.122,N
9 Mar 2024,first,43.872,N,47.153,N
9 Mar 2024,second,44.814,N,47.467,N
9 Mar 2024,third,45.318,N,46.804,N
16 Mar 2024,first,42.63,N,45.203,N
16 Mar 2024,second,43.348,N,45.195,N
16 Mar 2024,third,42.968,N,45.468,N
6 Apr 2024,first,43.58,N,45.644,N
6 Apr 2024,second,43.556,N,46.157,N
6 Apr 2024,third,44.345,N,46.875,N
27 Apr 2024,first,44.158,N,46.154,N
27 Apr 2024,second,43.132,N,45.947,N
27 Apr 2024,third,44.294,N,46.945,N
11 May 2024,first,43.377,N,45.381,N
11 May 2024,second,43.749,N,45.655,N
11 May 2024,third,44.66,N,45.983,N
25 May 2024,first,42.76,N,,
25 May 2024,second,42.855,N,,
25 May 2024,third,42.58,N,,
30 May 2024,first,43.037,N,43.906,N
30 May 2024,second,42.746,N,44.449,N
30 May 2024,third,,,44.783,N
1 Jun 2024,first,44.49,N,44.298,N
1 Jun 2024,second,42.616,N,44.508,N
8 Jun 2024,first,43.511,N,44.702,N
8 Jun 2024,second,42.35,N,43.255,N
8 Jun 2024,third,,,44.578,N
15 Jun 2024,first,42.936,N,43.919,N
15 Jun 2024,second,43.799,N,43.56,N
15 Jun 2024,third,42.337,N,,
16 Jun 2024,first,42.904,N,43.29,N
16 Jun 2024,second,42.977,N,43.299,N
16 Jun 2024,third,42.856,N,,
29 Jun 2024,first,42.055,N,43.123,N
29 Jun 2024,second,42.451,N,44.173,N
29 Jun 2024,third,44.046,N,45.176,N
6 Jul 2024,first,42.061,N,43.611,N
6 Jul 2024,second,43.946,N,43.811,N
6 Jul 2024,third,43.841,N,44.593,N
13 Jul 2024,first,44.863,N,43.585,N
13 Jul 2024,second,43.511,N,43.903,N
13 Jul 2024,third,44.179,N,43.077,N
27 Jul 2024,first,44.961,N,43.416,N
27 Jul 2024,second,44.862,N,44.054,N
27 Jul 2024,third,43.773,N,43.853,N
24 Aug 2024,first,43.482,N,43.847,N
24 Aug 2024,second,44.832,N,44.05,N
24 Aug 2024,third,43.846,N,45.388,N
21 Sep 2024,first,43.808,N,42.659,N
21 Sep 2024,second,42.964,N,43.199,N
21 Sep 2024,third,44.587,N,43.266,N
28 Sep 2024,first,43.664,N,43.09,N
28 Sep 2024,second,44.622,N,44.502,N
28 Sep 2024,third,44.211,N,44.249,N
12 Oct 2024,first,43.461,N,43.837,N
12 Oct 2024,second,43.144,N,44.948,N
12 Oct 2024,third,48.632,Y,43.086,N
19 Oct 2024,first,43.867,N,44.222,N
19 Oct 2024,second,43.37,N,43.47,N
19 Oct 2024,third,43.485,N,43.822,N
26 Oct 2024,first,43.809,N,46.171,N
26 Oct 2024,third,45.586,N,42.802,N
2 Nov 2024,first,43.623,N,43.414,N
2 Nov 2024,second,42.489,N,43.836,N
2 Nov 2024,third,43.175,N,44.739,N
9 Nov 2024,first,43.655,N,42.123,N
9 Nov 2024,second,44.947,N,43.396,N
9 Nov 2024,third,44.683,N,41.991,N
First Pass Over the Data
If you've read all the comments, you've seen a few that raise the issue of having all the methodology sorted before turning on the data logger. As a STEM worker it is pretty awesome to see ideas like pre-registration of hypotheses and methods popping up in mtb enthusiast social media. But as a practical matter, bear in mind that most serious research sits on a foundation of a serious literature review and the shared experience of mentors and colleagues. That's how anyone can get started designing without starting with observations. If you don't know and can't ask anyone, then you need to do a pilot study to learn the variability of the phenomenon you're interested in and to estimate the effect sizes of the factors you suspect may explain the variability. Those are prerequisite to determining sample size requirements. But they're not in an academic journal or a pinkbike article. So maybe this entire 2024 project's data will all have to be burned in order to learn those basics, any conclusions drawn being set aside as suggestive at best, and it will all go towards setting up more refined hypotheses and methods for the next data set (cause you can't use these twice). So be it, then. See you in 2025!
First Pass, Continued
If we apply the rules from the first post, then any run which got flagged as a not-full-effort lap should be considered for removal. Next, any session that failed to produce a complete set of six runs A1, B1, A2, B2, A3, B3, should be considered for removal. Despite originally being focused on a question about bike equipment, the question of multiple runs per session jumped out as potentially interesting right in the first few observations (the pilot of the pilot 😄). How large a sample should a bike tester do? Certainly not 100. I'd argue that 1 per product or setup is really not enough, though I understand why that is so common in mtb media, and 1 sometimes can provide a lot of insight. This thread is a space where people are exploring the idea of more than 1. Between 2 and 100, how many? If the tester's time is fixed, more runs/day means a bigger sample size. If the test's sample size is fixed, more runs/day means fewer days testing. But there may be a tradeoff between more runs/day and confounding the outcome of the test. It's not a simple question. Being able to quantify the size of the impact of multiple runs could help to inform that decision.
After removing the observations excluded by these criteria, the data set has been reduced to this:
These are some basic descriptive statistics, from which we can glean something. Two-way repeated measures ANOVA in the next post for the promised null hypothesis significance testing. p < 0.05 yew!!
Analysis
I chose this online tool because it is freely available and because of the emphasis it puts on the assumptions of each test. Statistical test results are so much science-flavored nonsense when the assumptions aren't discussed with all the receipts ready to be shown.
* This is why when one time in a session got flagged, all six times from the session had to be thrown out. Another, more complex model without the "balanced" assumption might have saved those five samples but this is the test I had chosen to use. Add that to the growing list of spots where subjectivity has crept into the process. Objectivity isn't in the science cred of the tools or the impartiality of the user and it's not a binary yes/no. It's a case you make to the best of your ability by showing the receipts.
Reminder: total sample size was 60 laps, 30 Bike A and 30 Bike B. Ouch!
Alert the media, we've struck gold!
Discussion
Effect size is a unit-less estimate of how much power the chosen factor (Bike Setup or Run Order) has to explain the outcome (Lap Time) in the model. It's a well known problem across science disciplines to put the number into ordinary language. "Small", "medium", what do they mean? But the advantage here is that we can directly compare the relative effect of Bike Setup versus Run Order. You may already have a sense of how your performance changes from your first and second sprint to your fifth and sixth when doing some interval training. But even if you don't, we can compare the effect size estimates of Bike Setup versus Run Order and see that the effect size of Run Order was over 10X larger for my test rider (me) in this test. I think that's a valuable insight.
Bike Setup B is 2.8 kg lighter than Bike Setup A. Carbon rims vs. aluminum. Lighter tires (but same tread design). And with 60 laps logged we can't detect any "statistically significant" difference between the mean lap times of A vs. B in this sprint challenge. Further, the estimated effect size (which I want to point out is independent of statistical significance) is estimated to be super small compared to how laps change over the course of doing six timed sprints.
I think that's interesting 🤩
Conclusions and considerations for future mtb data projects for readers and test riders (as promised at the top)
Say you want to jump on the trend of more data in your mtb content or more empirical testing. Say you are sample size ≥ 2 curious. How many test runs do you do and how do you deal with and talk about variability?
I found that measuring 6 runs per day compared to 2 runs per day dragged my times up by 0.543 seconds on average. I also found that the difference in average lap times attributable to the differences in my two test bikes was only 0.074 seconds.
The difference between how the two bikes performed on this test was so small as to be nearly undetectable. One possible way to improve the detection ability of the test is to increase sample size. But increasing sample size by way of measuring 4 additional full-effort laps per day changed the mean lap time by 7X more than switching bikes did.
I had a lot of fun, but for all the effort I ended up learning more about the test rider than the equipment. This may be the case with many product reviews.
I don't love all the numbers increasingly present in mtb media. If you've seen my posts, you've seen my distrust of scientism in cycling. But if you want the numbers and want them to be useful, there is a ton of work left to pitch in.
Thanks all!
Post a reply to: 140 laps A/B test data -- considerations for future mtb data projects for readers and test riders